
Социологи питерской Вышки — студенты и преподаватели — ведут наукометрический блог Pandemic Science Maps. В нем публикуются обзоры и подборки литературы и препринтов о коронавирусе и текущей пандемии, а также рекомендуются важные статьи из смежных областей.
Наукометрия обычно упоминается в связи с оценкой цитируемости, но базы Web of Science и Scopus ученые всего мира используют не для этого, а для информационного поиска. По итогам такого поиска строятся карты науки — наглядное отражение того, как устроены исследовательские области, и какие работы в них центральные. Блог Pandemic Science Maps показывает, как устроена наука об эпидемиях в отдельных ее разделах. Редакторы блога — Даниил Александров и Алла Лосева.
Когда во всём мире чрезвычайная ситуация, исследователи стремятся публиковать свои результаты в свободном доступе и как можно быстрее. Доступный вариант — опубликовать препринт, работу, которая ещё не прошла рецензию и оценку качества, зато быстро попадает в открытый доступ онлайн. В этом обзоре мы показываем, на какие тематики дробятся препринты о коронавирусе SARS-CoV-2 и вызванном им заболевании COVID-19, и как эти темы менялись с января по май 2020.
В обзоре мы, где возможно, приводим в качестве источников препринты систематических обзоров и мета-анализов. Подчеркнём, что приведённые исследования не прошли экспертную оценку, и ими не следует руководствоваться на практике.
В апрельском обзоре мы выделили три основные области исследований о новом коронавирусе:
- вирусология и молекулярная биология, где обсуждается сам вирус и вызванные им изменения на клеточном уровне;
- клиническая медицина, где обсуждаются вызванные вирусом болезни и их клинические характеристики;
- эпидемиология и исследования здравоохранения, где обсуждаются пути передачи вируса и меры сдерживания эпидемии.
Спустя месяц, данных о препринтах стало достаточно, чтобы рассмотреть их более детально. Для этого мы используем тематическое моделирование и анализируем заголовки и аннотации препринтов. Алгоритм статистически оценивает на текстовых данных, насколько близки друг другу используемые слова, и автоматически группирует их в кластеры. Эти кластеры мы можем интерпретировать как содержательные темы.
Мы пользуемся алгоритмом структурного тематического моделирования, который для каждого документа показывает, какие темы для него специфичны, и для каждой темы — какие слова для неё наиболее характерны. Таким образом, мы можем оценить, в какой пропорции в наших данных присутствует та или иная тема. Алгоритм также позволяет проанализировать, как на распределение тем влияют характеристики текстов: в нашем случае, это платформа, где препринт опубликован, и дата публикации.
Тематики препринтов
Взяв тексты аннотаций и заголовков препринтов, мы построили модель, которая выделила в этих данных 18 тем. На иллюстрацииони отсортированы по тому, насколько выражено их присутствие в массиве препринтов. Каждая тема сопровождается пятью самыми характерными для неё терминами.
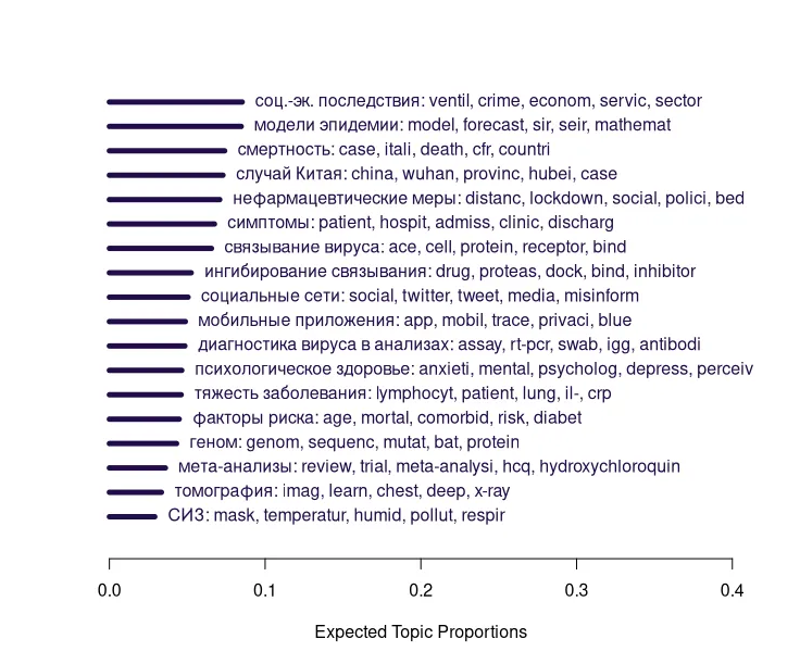
Темы сопровождаются пятью самыми характерными для них терминами, укороченными до основы.
К примеру, самую популярную тему можно интерпретировать как социально-экономические контексты и последствия пандемии и карантина. В препринтах, где выражено её присутствие, обсуждается готовность национальных систем здравоохранения к эпидемии — например, Craig, Kalanxhi, and Hauck (2020) оценивают оснащённость и количество отделений интенсивной терапии в Африке.
Также появляются исследования того, как карантин влияет на преступность. Campedelli, Aziani, and Favarin (2020) и Ashby (2020) отмечают снижение преступности в городах США. Что логично, снижается число грабежей, но число угонов и краж со взломом почти не меняется. Как не меняется и статистика по домашнему насилию, а в Великобритании даже снижается — однако Halford et al. (2020) объясняют это тем, что, будучи вынужденными постоянно находиться рядом с насильниками, жертвы просто не могут сообщать о преступлениях в полицию.
Самая узкая тема интерпретируется как условия, влияющие на передачу вируса: ношение средств индивидуальной защиты, в первую очередь масок, а также факторы окружающей среды — температура и влажность. Авторы систематических обзоров подчёркивают, что эффективность тканевых масок напрямую зависит от того, правильно ли ими пользуются и надёжно ли они прилегают к лицу (Mondal, Das, and Goswami 2020). Поскольку клинические испытания эффективности масок в условиях коронавирусной инфекции ещё не проводились, Wei et al. (2020) делают обзор таких работ в контексте заболеваний, подобных гриппу. Авторы обнаруживают, что ношение маски снижает риск развития заболевания, особенно когда маски носят все, независимо от наличия или отсутствия симптомов.
Модель, к примеру, выделяет и такую тему, как отслеживание контактов через мобильные приложения и данные о перемещениях. Во время эпидемии важно как можно раньше выявлять заражённых, и мобильные приложения позволяют намного быстрее получать данные о взаимодействиях между людьми. Даже если приложением пользуюся только 20% населения, они всё равно оказываются полезнее традиционных способов отслеживания контактов через интервью с заболевшими (Kretzschmar et al. 2020).
Ещё одну тему можно интерпретировать как влияние социальных сетей на поведение — через распространение (дез)информации. Milani (2020) на данных Фейсбука изучает, как следование практикам физического дистанцирования зависит от кросс-граничных социальных связей. Автор показывает, что на восприятие риска и социальное поведение влияют истории из-за рубежа, особенно из Италии и США.
Тематические контексты
В каких контекстах темы обсуждаются в препринтах, можно оценить по следующей иллюстрации. Размер узла в этой сети соответствует относительной популярности темы в массиве препринтов. Плотность линий показывает силу связи между темами, исходя из их совместной встречаемости в препринтах.
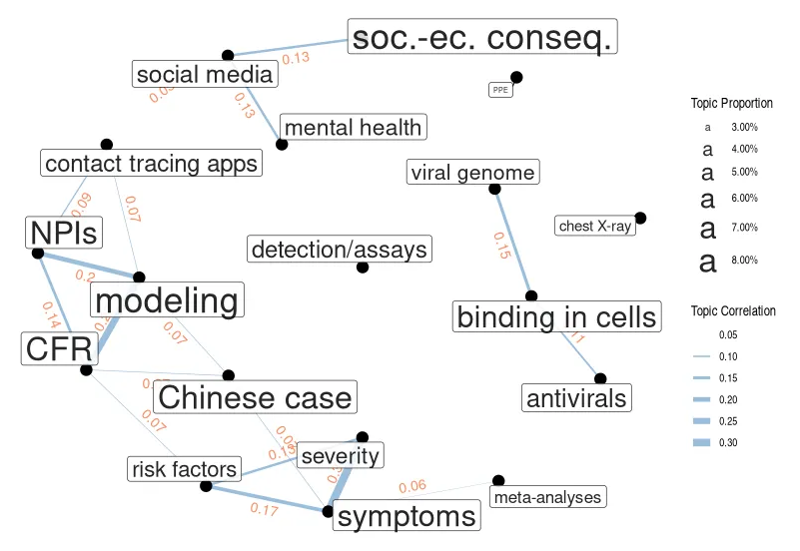
Связи обозначают, что темы упоминались вместе в одних и тех же описаниях препринтов. Ширина линий соответствует весу связей, то есть силе корреляции (отображены только связи с показателем корреляции больше 0.05). Размер названия темы соответствует популярности темы в массиве данных.
Например, заметно, что вопросы психологического здоровья — тревожность, воспринимаемые риски — иногда тоже обсуждаются в контексте (дез)информации, поступающей из Твиттера и других социальных сетей.
Тема моделирования заметно связана с темой нефармацевтических мер (non-pharmaceutical interventions, NPIs), в контексте моделирования эффектов от карантина и социальной изоляции, и с уже упомянутой темой отслеживания контактов через мобильные устройства, поскольку эти данные также используются для построения моделей.
К примеру, моделируя случай Бостона, Aleta et al. (2020) совмещают данные о перемещениях, полученные с мобильных устройств, с демографическими данными. Исследователи делают вывод, что одновременно запущенные нефармацевтические меры, тестирование на вирус и отслеживание контактов позволяют выявить и отправить на карантин 9% распространителей инфекции, у которых болезнь протекает бессимптомно. Благодаря снижению передачи вируса, в свою очередь, становится возможно снять ограничения на экономическую деятельность, не допуская при этом перегрузки системы здравоохранения.
Темы, связанные с клинической медициной — тяжесть заболевания, сопутствующие болезни и факторы риска, симптомы болезни, — формируют отдельную группу. Особняком стоят биологические темы про геном вируса, молекулярные механизмы связывания вируса в клетке и подавление этого процесса.
Вы также можете в интерактивном режиме оценить наполнение тем и близость между ними. Визуализация по ссылке показывает, какие слова наиболее релевантны каждой теме, и с какими темами в наибольшей степени соотносится то или иное слово. Для примера мы выделили основу isol (изол-). Заметно, что она наиболее характерна для темы 5 про нефармацевтические меры, где относится к мерам физического дистанцирования, а также для темы 14 про геном вируса, где упоминается в контексте изоляции вируса.
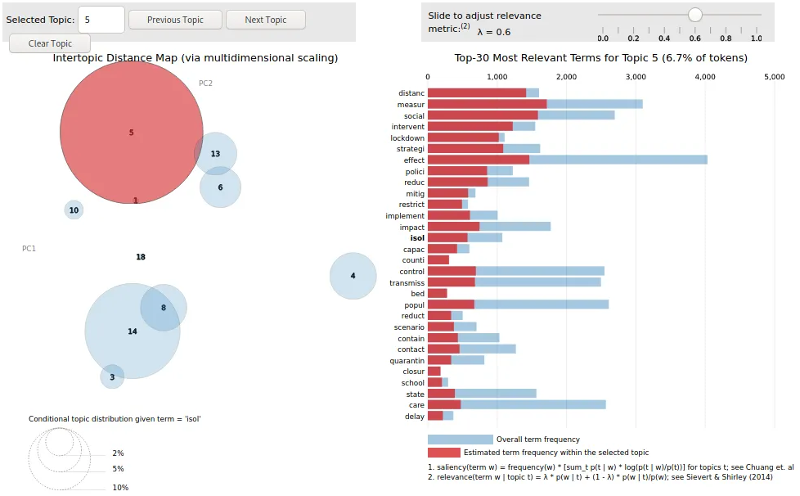
Размеры кругов соответствуют выраженности темы в массиве данных (в данном случае — насколько тема представлена в препринтах, содержащих термин isol-; подсвечена тема, соответствующая этому слову больше всего). Столбчатый график справа отображает 30 слов, в наибольшей степени характеризующих выделенную теме, с заданным параметром исключительности λ. Чем ниже значение параметра, тем более редкие слова отображаются справа — термины, уникальные для выделенной темы. Чем выше значение параметра, тем более частотные и в том числе более общие слова отображаются. Красные столбцы показывают, насколько часто слово встречается в выделенной теме, а синие — насколько часто оно встречается в полном массиве данных
К маю среди препринтов о новом коронавирусе продолжают отчётливо выделяться темы, связанные с клинической медициной и с вирусологией. Блок работ про распространение пандемии теперь дробится на два. Часть исследований используют эпидемиологические модели, чтобы изучать передачу вируса и эффект нефармацевтических мер. Другая часть препринтов основаны на статистических данных и анализируют социально-экономические и психологические контексты и последствия эпидемии.
Динамика тем
За четыре месяца, прошедшие с января, относительная популярность менялась далеко не у всех тем из полученного нами набора. Поэтому из 18 тем, выделенных на предыдущем этапе, мы отобрали темы, которые показали видимые и статистически значимые различия в том, насколько представлены они были в массиве препринтов.
На рисунке показано, как менялась относительная популярность семи заметных тем. (В график не включена динамика раньше 15 февраля, поскольку в месяц, предшествующий этой дате, было не так много публикаций, и репрезентация получается ненаглядной.)
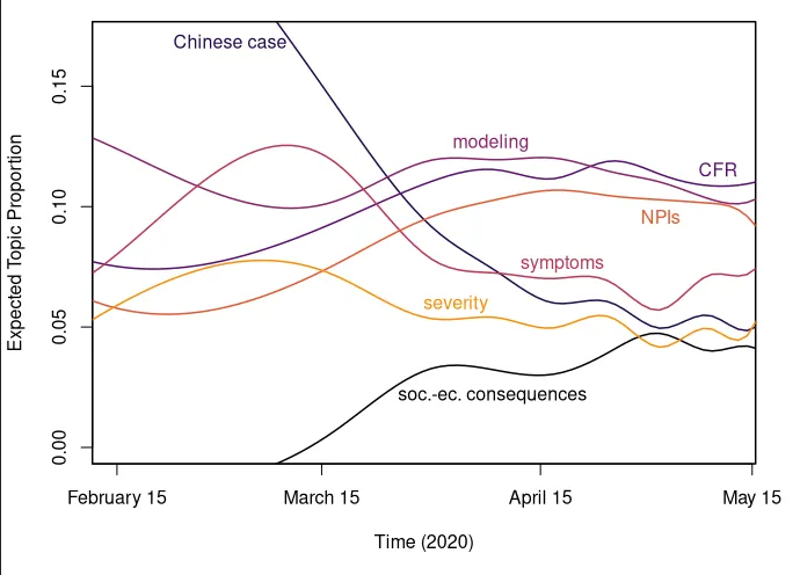
Три темы из этих семи постепенно снижают своё присутствие после отчётливого роста ранней весной.
Во-первых, это препринты, посвящённые китайскому случаю и клиническим характеристикам первых китайских пациентов с COVID-19. На январь эта тема занимала треть всего массива текстов, в том числе из-за небольшого числа исследований в целом. К маю её доля снизилась до 5%, что связано с распространением эпидемии в другие страны и повсеместный рост числа препринтов.
Также меньшую долю в массиве препринтов стала занимать тема про симптомы COVID-19, так как основные исследования на этот счёт уже вышли и постепенно публикуются в журналах (напр., мета-анализ Zhu et al. 2020).
По той же причине несколько снизилась популярность темы про клинические характеристики больных, у которых болезнь протекает особенно тяжело (severity). Один из систематических обзоров на эту тему уже стал полноценной публикацией (Yang et al. 2020).
Другие темы остаются или становятся популярными.
Тема про моделирование распространения эпидемии остаётся популярной, хотя становится чуть менее представленной в массиве текстов.
Возможно, потому, что одновременно с этим набирает вес тема про нефармацевтические меры (NPIs), которая также включает в себя моделирование, с моделями снятия ограничений на социальную и экономическую жизнь.
Среди препринтов на тему моделирования, вышедших в последний месяц, есть работы, «надстраивающие» стандартную модель SIR за счёт добавления класса «невыявленных» распространителей инфекции. Это важно, поскольку люди, переносящие инфекцию бессимптомно, составляют до 16% всех заразившихся (согласно препринту мета-анализа Byambasuren et al. 2020). Кроме того, человек начинает передавать вирус за 1–3 дня до появления первых симптомов, и половина всех случаев передачи вируса происходят именно в этот период (Casey et al. 2020). Так что невыявленные распространители инфекции заметно влияют на картину эпидемии.
Включая этот класс людей в модель, Charpentier et al. (2020) делают вывод, что оптимальная стратегия внедрения нефармацевтических мер такова: быстрый и жёсткий карантин, короткий переходный период, долгий период, когда отделения интенсивной терапии работают на полную мощность, и снятие ограничений. Симуляции Bej and Wolkenhauer’s (2020) показывают, что проактивное тестирование — даже тех, кто не демонстрирует симптомов заболевания — подкрепляет нефармацевтические меры. Как предполагают авторы, развитое проактивное тестирование позволяет контролировать эпидемию уже после снятия ограничений вплоть до начала вакцинации, без необходимости повторно вводить карантин.
Karatayev, Anand, and Bauch (2020) моделируют снятие ограничений, основываясь на канадских данных. Из препринта следует, что отменять карантин лучше на уровне округов, ориентируясь на местную эпидемиологическую ситуацию, нежели на уровне всей провинции на основании агрегированной статистики. Тем не менее, отмена ограничений на местном уровне должна координироваться на уровне провинции, и уровень тестирования должен быть примерно одинаковый во всех округах.
Публикации с оценкой уровня смертности (case-fatality rate, CFR) и основного репродуктивного числа R0 занимают заметное место в массиве данных, поскольку в ходе пандемии оценки продолжают обновляться. В мае вышло ещё два посвящённых им препринта мета-анализов.
Yadav and Yadav (2020) обнаружили, что, исходя из данных предыдущих исследований, R0 находится примерно на уровне 3.11 человек, а уровень смертности составляет 2.56%. Это означает, что один заражённый человек может передать инфекцию двум-трём, если не приняты никакие меры контроля над эпидемией, а 3% заразившихся могут умереть от болезни. Canelo-Aybar et al. (2020) дают схожую оценку, 2.8% смертности в среднем и 2.1% в странах с развитым тестированием на вирус. Авторы подчёркивают, что этот уровень зависит от доли населения старше 65 лет, но не от числа врачей или мест в отделениях интенсивной терапии.
Самая быстрорастущая тема — социально-экономические контексты и последствия эпидемии. Препринты в этой теме только начинают появляться.
Например, Craig, Kalanxhi, and Hauck (2020) указывают на низкую или ограниченную готовность отделений интенсивной терапии в странах Африки, а Milani (2020) даёт ранние оценки возможной безработицы из-за эпидемии.
Тема психологического здоровья, хотя и не вошла в график, тоже понемногу становится более заметной. Qi et al. (2020) изучают психологическое состояние пациентов с COVID-19 и показывают, что у многих из них возникают нарушения психического здоровья, появляются симптомы тревожности и/или депрессии, а у некоторых и пост-травматического стрессового расстройства. Когда такие пациенты чувствуют, что сталкиваются со стигматизацией, риски для психологического здоровья возрастают, а воспринимаемая социальная поддержка снижает эти риски.
Wissmath et al. (2020) обнаруживают, что в целом у населения наблюдается повышенный уровень стресса из-за страха заболеть. Что важно, те люди, кто не одобряет нефармацевтические меры контроля, живёт в регионах с большим числом заболевших, и волнуется о последствиях кризиса, демонстрируют ещё более высокие уровни стресса. А вот работа в системе здравоохранения, или работа, которая требует физического присутствия, не добавляют стресса. И, как и в предыдущем препринте, воспринимаемая социальная и правительственная поддержка снижают уровень стресса. Исходя из этого, исследователи рекомендуют представителям власти оказывать поддержку населению и обсуждать волнующие людей вопросы, в том числе объяснять необходимость нефармацевтических мер контроля.
Данные и методы
Nicholas Fraser разработал и выложил в открытый доступ всю процедуру и код для сбора данных — спасибо ему. На figshare он детально комментирует процедуру. Вкратце: мы собираем данные о препринтах из репозиториев Crossref (где индексируются препринты, опубликованные на многих платформах) и arXiv. Для анализа мы отбираем только те препринты, в заголовках и аннотациях которых встречаются термины coronavirus,covid-19, sars-cov, ncov-2019, 2019-ncov. К этому ряду мы добавили corona virus, в раздельном написании, чтобы находить больше релевантных документов.
В итоге на 17 мая 2020 г. мы собрали 8722 релевантных препринтов. Здесь показано, как со временем росло их количество.
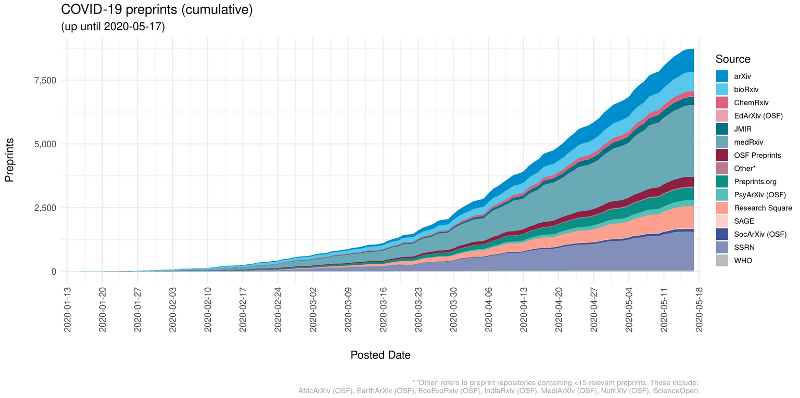
Платформы, где было опубликовано менее 15 препринтов за данный период, объединены под категорией Other.
Чтобы увеличить объём данных для анализа тем, мы соединили заголовки и аннотации препринтов. Затем мы почистили эти объединённые тексты, удалив пунктуацию и нерелевантные символы. Также мы удалили из текстов слова, формально описывающие структуру исследования (abstract, summary, methods, research и пр.), слова, обозначающие новый коронавирус, и слишком общие понятия здравоохранения (coronavirus, SARS-CoV-2, health, pandemic, country и пр.), поскольку они встречаются почти в каждом тексте и не говорят о специфике темы.
Затем мы отфильтровали большую часть документов не на английском языке. Поскольку в мета-данных о препринтах нет информации о языке публикации, мы пользовались пакетом textcat, чтобы автоматически определить язык текста. Ряд текстов алгоритм ошибочно классифицировал как неанглоязычные, а некоторые тексты не на английском — не распознал. Мы решили удалить только те тексты, которые алгоритм идентифицировал как неанглоязычные и которые были опубликованы на Open Science Framework, где находилось большинство неанглоязычных публикаций. Это позволило нам сохранить в данных тексты, отнесённые к неанглоязычным по ошибке. Таким образом, в нашем массиве остаются некоторые неанглоязычные тексты, но в незначительном количестве, что не влияет на разбиение по темам. В итоге из 8722 препринтов для анализа осталось 8650.
Мы построили структурную тематическую модель, пользуясь пакетом stm. Для моделирования мы сократили все слова до их основ и оставили для анализа только те слова, которые как минимум дважды встречались в массиве текстов. Источник и дата публикации препринта использовались как ковариаты в модели. Поскольку число тем задаётся исследователем, мы остановились на решении, которое разбивает массив данных на 18 тем. Модель с такими параметрами сошлась на шаге 87.